Professor by special appointment of Low Saxon / Groningen Language and Culture
Center for Groningen Language and Culture
Martijn Wieling is Professor by special appointment of Low Saxon / Groningen Language and Culture at the Center for Groningen Language and Culture and an Associate Professor (UHD1) at the University of Groningen. His research focuses on investigating language variation and change quantitatively, with a specific focus on the Low Saxon language. He uses both large digital corpora of text and speech, as well as experimental approaches to assess differences in the movement of the tongue and lips during speech. More information about the research conducted in his group can be found on the website of the Speech Lab Groningen. Since 2019, he is a member of the Global Young Academy.
Center for Groningen Language and Culture
University of Groningen, Department of Information Science
University of Groningen, Department of Information Science
University of Groningen, Department of Information Science
University of Tübingen, Department of Quantitative Linguistics
Ph.D. in Linguistics (cum laude)
University of Groningen, Faculty of Arts
Master (research) of Science in Behavioural and Cognitive Neurosciences (cum laude)
University of Groningen, Faculty of Science and Engineering
Master of Science in Computing Science
(cum laude)
University of Groningen, Faculty of Science and Engineering
Bachelor of Science in Computing Science
(cum laude)
University of Groningen, Faculty of Science and Engineering

This five-year research grant was awarded to Wieling and PhD student Teja Rebernik by the Netherlands Organisation for Scientific Research (NWO) for their project "Speech planning and monitoring in Parkinson's disease".

Wieling was selected as one (out of 600+ applications) of the 43 new members of the Global Young Academy (DJA) in May 2019 for a period of five years. The Global Young Academy gives a voice to young scientists around the world. To realise this vision, the GYA develops, connects, and mobilises young talent from six continents. Moreover, the GYA empowers young researchers to lead international, interdisciplinary, and inter-generational dialogue with the goal to make global decision making evidence-based and inclusive.


In 2016, Wieling was selected as one of the 18 founding members of the Young Academy of Groningen for a period of five years. The Young Academy Groningen is a club for the University of Groningen’s most talented, enthusiastic and ambitious young researchers. Members come from all fields and disciplines and have a passion for science and an interest in matters concerning science policy, science and society, leadership and career development.

Wieling was selected as one of the youngest members of De Jonge Akademie (DJA) of the Royal Netherlands Academy of Arts and Sciences (KNAW) in April 2015 for a period of five years. In 2018, Wieling was elected as vice-chairman of De Jonge Akademie for a period of two years.The Young Academy is a dynamic and innovative group of 50 top young scientists and scholars with outspoken views about science and scholarship and the related policy. The Young Academy organises inspiring activities for various target groups focusing on interdisciplinarity, science policy, and the interface between science and society.




This four-year research grant was awarded to Wieling by the Netherlands Organisation for Scientific Research (NWO) for his project "Improving speech learning models and English pronunciation with articulography". Only 15.5% of the submitted project proposals were granted.
This one-year research grant was awarded to Wieling by the Netherlands Organisation for Scientific Research (NWO) for his project "Investigating language variation physically". Only 12% of the submitted project proposals were granted.
My research generally focuses on quantitatively investigating patterns in language variation and change. While I mostly investigate dialect variation, I also study the pronunciation of second language learners, congenitally blind speakers, or speakers with dysarthria (such as Parkinson's disease, or due to tongue resection in oral cancer patients). Besides investigating pronunciation, I am interested in identifying patterns in large, digitally available corpora of text. For example, in collaboration with the law department, we are currently investigating how we may predict court judgments on the basis of various legal and linguistic characteristics of the court transcripts. This project also emphasizes the interdisciplinary and collaborative nature of my research (see also projects, below).
For investigating patterns in speech, I generally take two approaches. The first approach is to analyze phonetically transcribed data using new quantitative, dialectometric techniques (see publications in Language, Journal of Phonetics, Annual Review of Linguistics, Language Dynamics and Change and PLOS ONE). The second approach is to track the movement of speakers' tongue and lips using (e.g.,) electromagnetic articulography (see several publications in Journal of Phonetics, and Journal of the Acoustical Society of America).
In terms of techniques, I am frequently using (and teaching courses about) generalized additive modeling, a flexible non-linear regression technique which can be used to model the influence of geography on dialect variation, but also to model time series data (such as collected using articulography, eye-tracking or EEG experiments). See this extensive tutorial (published in Journal of Phonetics), but also publications in Language, Journal of Phonetics and PLOS ONE. More information about my research can be foun on the Speech Lab Groningen website.


(PhD students: Martijn Bartelds and Wietse de Vries)
In this Google-funded project, we will develop community-specific applications to teach the local Groningen variety to primary school children. This project originated through a collaboration with Dorpsbelangen Zandeweer, Eppenhuizen en Doodstil. The game has launched and can be freely downloaded for Apple and Android.

(PhD student: Teja Rebernik, Co-supervisors: Roel Jonkers and Aude Noiray)
Despite doing it almost without effort, speaking is a highly complex task requiring precisely timed and linguistically driven coordination of the lungs, vocal folds and speech articulators (e.g. lips, tongue). This process, speech motor control, relies on both feedforward (pre planned movements based on stored movement representations drawn from past experiences) and feedback (monitoring sensory input relative to what is expected) control mechanisms. Research suggests that these mechanisms may be impaired in Parkinson’s disease (PD) patients. However, current findings have resulted from studies with small samples and heterogeneous PD groups.
The central aim of this project is to identify which speech control mechanisms in PD patients are impaired and to what extent by comparing newly diagnosed PD patients, advanced stage PD patients, and healthy adults. Specifically, we will investigate how participants cope with feedback perturbations in speech, by measuring both the resulting acoustic speech signal and the underlying speech motor articulation using electromagnetic articulography and ultrasound tongue imaging. To assess whether the potential impairments of the feedback and feedforward system are speech-specific or more general (as PD is a movement disorder), we will also conduct feedback perturbation experiments in non-speech motor movement tasks.
The innovative combination of these methods will enable us to identify whether and how impairments of speech planning and monitoring are related to the progression of PD. Furthermore, the extent to which PD patients cope with feedback perturbations compared to healthy adults may potentially serve as a diagnostic marker for the disease. This would be highly relevant in our aging society.
(PhD student: Martijn Bartelds, Co-supervisor: Nanna Hilton)
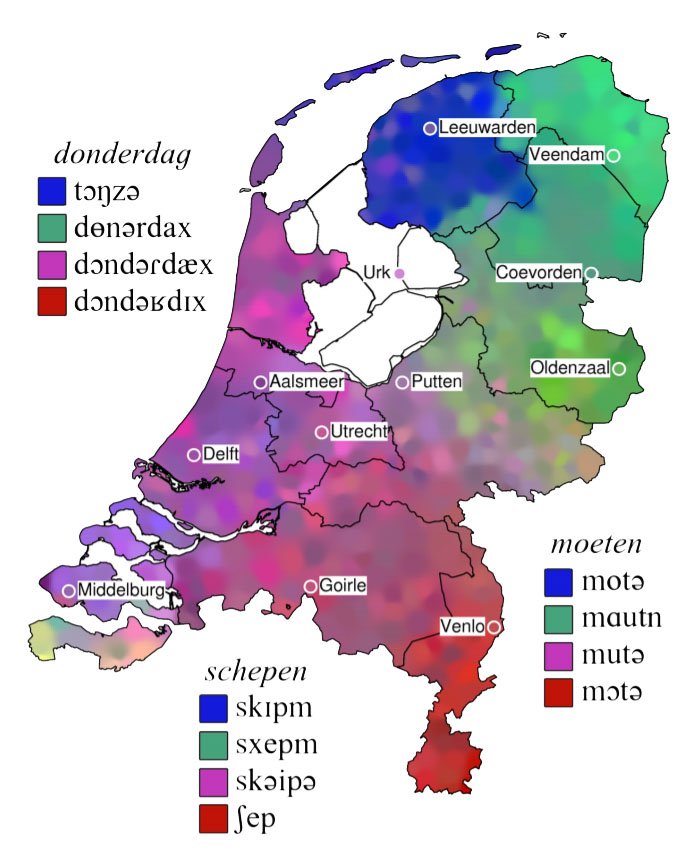
In this project we aim to investigate (using a data-driven approach) how pronunciation variation in the province of Groningen and the Low Saxon language area is distributed geographically and how it has changed over time. In addition, we will investigate if it is possible to automatically rate how similar someone's pronunciation is to a specific regional target pronunciation. Finally, we aim to identify how many people speak a dialect and if this affects cognition. This project is funded by both the Center for Groningen Language and Culture, the Faculty of Arts of the University of Groningen and the Centre for Digital Humanities of the University of Groningen.

(PhD student: Masha Medvedeva, Co-PI: Michel Vols)
Law is everywhere: almost every human activity is regulated. Buying a sandwich, renting an apartment or going to a hospital, all these activities involve legal rules and consequences. For a stable and sustainable society it is essential that its laws are predictable. People need to know what a legal rule means and what likely outcome a potential court case will have. Authorities have tried to improve the law's predictability and transparency by publishing court judgments. For decades, summaries of judgments were published in written journals, which were not easily accessible for the public. Nowadays, courts publish their judgments online. For example, approximately 370,000 individual court judgments can be found on the website of the Dutch judiciary (www.rechtspraak.nl). Similarly, another 52,000 court judgments are published online by the European Court of Human Rights (http://hudoc.echr.coe.int). Each of these judgments contains a detailed and rich description of the facts, procedure, reasoning of the parties and outcome of the case. Of course, public availability of case law will help to improve predictability and transparency, but to analyse hundreds of thousands of legal documents, we need other approaches than the traditional and labour-intensive 'doctrinal analysis' (i.e. close reading of a single or a small number of judgments) conducted by legal researchers.
The goal of this PhD project is therefore to combine two distinctly separate disciplines, law and computational linguistics, in developing and evaluating quantitative, computational approaches to improve the predictability and transparency of the law. Techniques from computational linguistics would (for example) enable the automatic extraction, syntactic and semantic analysis of the judgment texts. The extracted features may be used in quantitative analyses identifying common patterns (see Wieling, 2012 for examples, albeit in a different field), which can subsequently be used to predict the outcome of a judgment. Such an approach would clearly be beneficial for the field of law. Surprisingly, a recent study (Vols & Jacobs, 2016) showed that between 2006 and 2016 fewer than 25 publications in Dutch legal journals were published involving statistics to analyse case law. While a quantitative approach to analysing case law is more prevalent in the US, it is primarily focused on specific American legal issues, and frequently contains serious methodological flaws (Epstein & King, 2002; Epstein & Martin, 2014).
In computational linguistics, specific characteristics of legal texts have been studied (see Francesconi, Montemagni et al. (eds.), 2010), but hardly any studies have attempted to use linguistic characteristics to predict judicial decisions. A very recent exception (also illustrating the timeliness of the project idea) by Aletras et al. (2016) reported an accuracy of 79% in predicting the judgments of the European Court of Human Rights. However, they focused only on a small sample (600 judgments) and used simplistic linguistic features (such as word frequency). The goal of this PhD project is therefore to take a more comprehensive, linguistically-oriented approach incorporating all available data, thereby developing a system which is able to detect common patterns in legal big data and use these to predict the outcome of a judgment.
This project is funded by the Young Academy Groningen.
(PhD student: Jidde Jacobi, Co-supervisors: Roel Jonkers, Michael Proctor, and Ben Maassen)
In this IDEALAB-funded project, we investigate speech articulation in Parkinson's disease. Parkinsons disease is a degenerative neurological disorder that is characterised by a decay of motor function. Due to a loss of dopaminergic cells in the substantia nigra, both motor control as well as initiation deteriorate over time, which frequently leads to difficulties in speech producation, a phenomenom that is known as hypokinetic dysarthria. Previous acoustics studies have shown that pitch height and variation, articulation of both vowels and consonants and voice quality are often affected in hypokinetic dysarthria. So far however, the role of kinematics in hypokinetic dysarthria has not been given much attention. Yet, thanks to the recent development of electromagnetic articulography (EMA) it is now possible to track and measure the kinematic movements of the lips, the tongue and the jaw during speech production. This means that a more fine-grained analysis of the articulation difficulties in hypokinetic dysarthria can be performed. In this future study, the velocity, amplitude and coordination of kinematic gestures will be under investigation. Specifically, the temporal overlap of speech gestures will be studied as well as the location and rate of contractions within the vocal tract. In total, 30 Parkinson’s patients with hypokinetic dysarthria will be included. Another 30 participants will serve as healthy controls. In doing so, a detailed view of coordination in hypokinetic dysarthria will be obtained which will lead to a better understanding of the speech disorder. Moreover, it will shed new light on leading theories that have only approached speech from an acoustic viewpoint. Ultimately, the knowledge that will be obtained within this study can improve a early diagnosis of Parkinson’s disease and also dramatically improve speech therapy. In addition, it will also provide more general insight into the kinematics of speech.
(Research assistant: Lisanne de Jong)
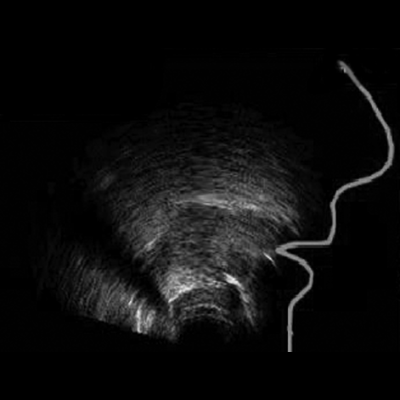
In this project we aim to investigate how visualizing tongue movements using ultrasound may be used to help a learner to improve his or her pronunciation in a second language (L2). This project is funded by the Groningen University Fund and De Jonge Akademie.

(Post-doc: Aki Kunikoshi, Data scientists: Herbert Kruitbosch and Arya Babai, Collaborator: David van Leeuwen)
In this project we focused on automatically detecting Dutch accents on the basis of data from the Sprekend Nederland data. Particularly, we were interested in identifying the acoustic and segmental characteristics of the different accents. This project is funded by the Centre for Digital Humanities of the University of Groningen. Some results of the project can be found here.

(Co-PI: Nanna Hilton, Post-doc: Aki Kunikoshi, Data scientists: Herbert Kruitbosch)
In this project, we have studied the effects of one language on another in our voices, by considering how recognizable Frisian phonological traits are in speakers' production of their first language, Frisian, as well as in their second language, Dutch. This project is funded by the University of Groningen (Data Science Projects 2017). A publication regarding this project is currently in preparation.

(Researcher: Pauline Veenstra, Collaborator: Royal Dutch Visio)
In this project we investigated if the speech of congenitally blind speakers differs from that of sighted speakers, both from an articulatory as well as an acoustic perspective. Specifically, we investigate if automatic speech recognition performance differs between the two groups. This project was funded by VIVIS. The results of the project were presented at several conferences (e.g., see here: page 88).

(Collaborators: Patti Adank, Mark Tiede, Andrea Weber, R. Harald Baayen and others)
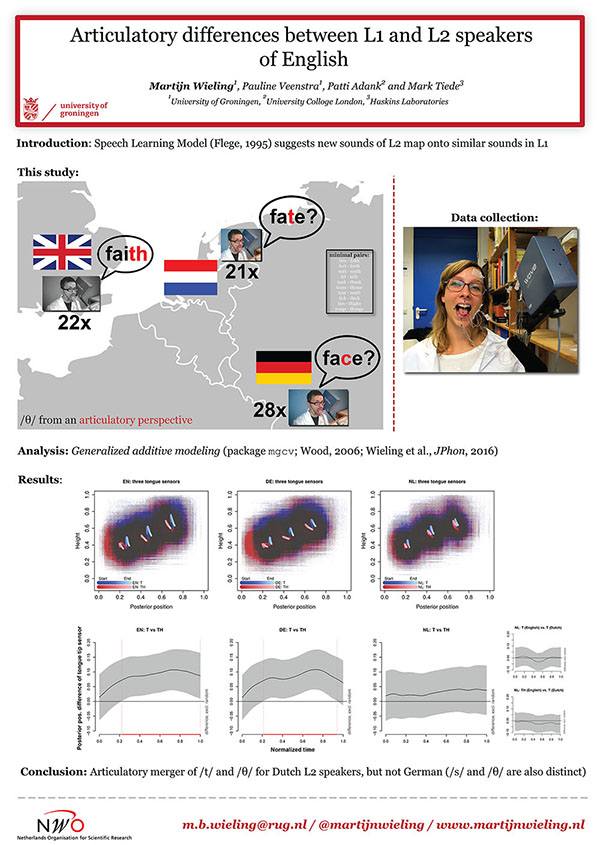
In this project we have investigated articulatory differences between Dutch and German speakers' pronunciation of English versus those of native English speakers. Furthermore, we are assessing how visual feedback of the speech articulators may help improve non-native speakers' pronunciation of English. This project was funded by NWO (Veni grant). Results of the project can be found in several publications.
(Collaborators: R. Harald Baayen and team members in Tübingen)
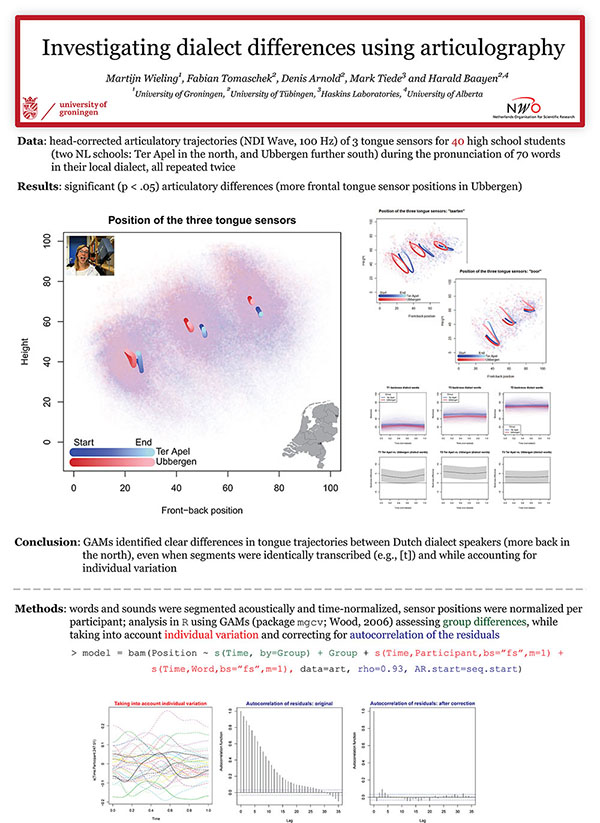
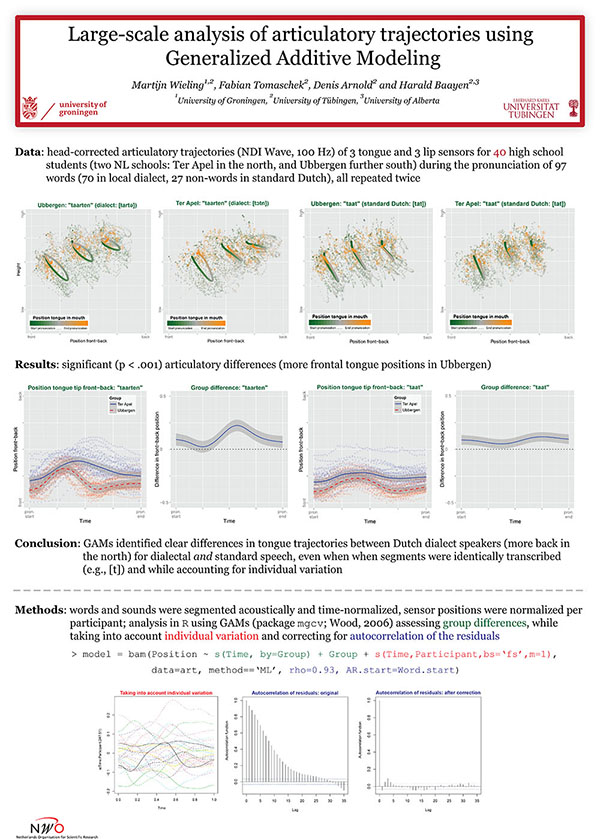
In this project (conducted at the University of Tübingen) we have investigated Dutch dialect variation using articulography. This project was funded by NWO (Rubicon grant). Results of the project can be found in several publications.
In Speech Lab Groningen, we have the following equipment available for research projects:

I am always looking for excellent PhD candidates or research assistants. If you are interested in the field of dialect or language variation, speech production research, or computational linguistics, please contact me.

Large phonetic corpora are frequently used to investigate language variation and change in dialects, but these corpora are often constructed by many researchers in a collaborative effort. This typically results in inter-transcriber issues that may impact the reliability of analyses using these data. This problem is exacerbated when multiple phonetic corpora are compared when investigating real time dialect change. In this study, we therefore propose a method to automatically and iteratively merge phonetic symbols used in the transcriptions to obtain a more course-grained, but better comparable, phonetic transcription. Our approach is evaluated using two large phonetic Netherlandic dialect corpora in an attempt to estimate sound change in the area in the 20th century. The results are discussed in the context of the available literature about dialect change in the Netherlandic area.
With the ever-growing accessibility of case law online, it has become challenging to manually identify case law relevant to one's legal issue. In the Netherlands, the planned increase in the online publication of case law is expected to exacerbate this challenge. In this paper, we tried to predict whether court decisions are cited by other courts or not after being published, thus in a way distinguishing between more and less authoritative cases. This type of system may be used to process the large amounts of available data by filtering out large quantities of non-authoritative decisions, thus helping legal practitioners and scholars to find relevant decisions more easily, and drastically reducing the time spent on preparation and analysis. For the Dutch Supreme Court, the match between our prediction and the actual data was relatively strong (with a Matthews Correlation Coefficient of 0.60). Our results were less successful for the Council of State and the district courts (MCC scores of 0.26 and 0.17, relatively). We also attempted to identify the most informative characteristics of a decision. We found that a completely explainable model, consisting only of handcrafted metadata features, performs almost as well as a less well-explainable system based on all text of the decision.
The present study examined the kinematics of maximal effort sprint running, mapping the relations among a person's maximal running speed, maximum running acceleration and the distance coverable in a certain amount of time by this person. Thirty-three participants were recruited to perform a simple sprint task. Both forward and backward running were considered. Participants' position, velocity and acceleration data were obtained using a Local Positioning Measurement system. Participants' speed-acceleration profiles turned out to be markedly non-linear. To account for these non-linear patterns, we propose a new macroscopic model on the kinematics of sprint running. Second, we examined whether target distance was of influence on the evolution of participants' running speeds over time. Overall, no such effect on running velocity was present, except for a 'finish-line effect'. Finally, we studied how variation in individuals' maximum running velocities and accelerations related to differences in their action boundaries. The findings are discussed in the context of affordance-based control in running to catch fly balls.
Although communicative language teaching (CLT) was thought to have revolutionized classroom practice, there are "weak" and "strong" versions (Howatt, 1984). Most foreign language classrooms in the world still favor weak versions with structure-based (SB) views on language (Lightbown & Spada, 2013), and practice in the Netherlands is not much different (West & Verspoor, 2016). However, a small group of teachers in the Netherlands started teaching French as a second language with a strong CLT program in line with Dynamic Usage-Based (DUB) principles. Rather than focusing on rule learning and explicit grammar teaching to avoid errors, the DUB program takes the dynamics of second-language development into consideration and focuses on the three key elements of usage-based theory: frequency, salience and contingency. These translate into a great deal of exposure, repetition, learning the meaning of every single word through gestures, and presenting whole chunks of language, all without explicit grammar teaching. This study aims to compare the effects of the SB and DUB instructional programs after three years. We traced the second-language development of 229 junior high school students (aged 12 to 15) learning French in the Netherlands over three years. The participants took three oral tests over the course of three years (568 interviews) and wrote seven narratives on the same topic (1511 narratives). As expected, the DUB approach, which is in line with a strong CLT version, was more effective in achieving proficiency in both speaking and writing and equally effective in achieving accuracy.
Deep acoustic models represent linguistic information based on massive amounts of data. Unfortunately, for regional languages and dialects such resources are mostly not available. However, deep acoustic models might have learned linguistic information that transfers to low-resource languages. In this study, we evaluate whether this is the case through the task of distinguishing low-resource (Dutch) regional varieties. By extracting embeddings from the hidden layers of various wav2vec 2.0 models (including a newly created Dutch model) and using dynamic time warping, we compute pairwise pronunciation differences averaged over 10 words for over 100 individual dialects from four (regional) languages. We then cluster the resulting difference matrix in four groups and compare these to a gold standard, and a partitioning on the basis of comparing phonetic transcriptions. Our results show that acoustic models outperform the (traditional) transcription-based approach without requiring phonetic transcriptions, with the best performance achieved by the multilingual XLSR-53 model fine-tuned on Dutch. On the basis of only six seconds of speech, the resulting clustering closely matches the gold standard.
Cross-lingual transfer learning with large multilingual pre-trained models can be an effective approach for low-resource languages with no labeled training data. Existing evaluations of zero-shot cross-lingual generalisability of large pre-trained models use datasets with English training data, and test data in a selection of target languages. We explore a more extensive transfer learning setup with 65 different source languages and 105 target languages for part-of-speech tagging. Through our analysis, we show that pre-training of both source and target language, as well as matching language families, writing systems, word order systems, and lexical-phonetic distance significantly impact cross-lingual performance. The findings described in this paper can be used as indicators of which factors are important for effective zero-shot cross-lingual transfer to zero- and low-resource languages.
Variation in speech is often quantified by comparing phonetic transcriptions of the same utterance. However, manually transcribing speech is time-consuming and error prone. As an alternative, therefore, we investigate the extraction of acoustic embeddings from several self-supervised neural models. We use these representations to compute word-based pronunciation differences between non-native and native speakers of English, and between Norwegian dialect speakers. For comparison with several earlier studies, we evaluate how well these differences match human perception by comparing them with available human judgements of similarity. We show that speech representations extracted from a specific type of neural model (i.e.~Transformers) lead to a better match with human perception than two earlier approaches on the basis of phonetic transcriptions and MFCC-based acoustic features. We furthermore find that features from the neural models can generally best be extracted from one of the middle hidden layers than from the final layer. We also demonstrate that neural speech representations not only capture segmental differences, but also intonational and durational differences that cannot adequately be represented by a set of discrete symbols used in phonetic transcriptions.
In this paper, we discuss previous research in automatic prediction of court decisions. We define the difference between outcome identification, outcome-based judgement categorisation and outcome forecasting, and review how various studies fall into these categories. We discuss how important it is to understand the legal data that one works with in order to determine which task can be performed. Finally, we reflect on the needs of the legal discipline regarding the analysis of court judgements.
In this paper we attempt to identify eviction judgements within all case law published by Dutch courts in order to automate data collection, previously conducted manually. To do so we performed two experiments. The first focused on identifying judgements related to eviction, while the second focused on identifying the outcome of the cases in the judgements (eviction vs.~dismissal of the landlord's claim). In the process of conducting the experiments for this study, we have created a manually annotated dataset with eviction-related judgements and their outcomes.
Second language (L2) learning has been promoted as a promising intervention to stave off age-related cognitive decline. While previous studies based on mean trends showed inconclusive results, this study is the first to investigate nonlinear cognitive trajectories across a 30-week training period. German-speaking older participants (aged 64-75 years) enrolled for a Spanish course, strategy game training (active control) or movie screenings (passive control). We assessed cognitive performance in working memory, alertness, divided attention and verbal fluency on a weekly basis. Trajectories were modelled using Generalized Additive Mixed Models to account for temporally limited transfer effects and intraindividual variation in cognitive performance. Our results provide no evidence of cognitive improvement differing between the Spanish and either of the control groups during any phase of the training period. We did, however, observe an effect of baseline cognition, such that individuals with low cognitive baselines increased their performance more in the L2 group than comparable individuals in the control groups. We discuss these findings against the backdrop of the cognitive training literature and Complex Dynamic Systems Theory.
Purpose: This study compares two electromagnetic articulographs (EMA) manufactured by Northern Digital, Inc.: the NDI Wave System (2008) and the NDI Vox-EMA System (2020).
Method: Four experiments were completed: (a) comparison of statically positioned sensors; 4(b) tracking dynamic movements of sensors manipulated using a motor-driven LEGO apparatus; (c) tracking small and large movements of sensors mounted in a rigid bar manipulated by hand; and (d) tracking movements of sensors rotated on a circular disc. We assessed spatial variability for statically positioned sensors, variability in the transduced Euclidean distances (EDs) between sensor pairs, and missing data rates. For sensors tracking circular movements, we compared the fit between fitted ideal circles and actual trajectories.
Results: The average sensor pair tracking error (i.e., the standard deviation of the EDs) was 1.37 mm for the WAVE and 0.12 mm for the VOX during automated trials at the fastest speed, and 0.35 mm for the WAVE and 0.14mm for the VOX during the tracking of large manual movements. The average standard deviation of the fitted circle radii charted by manual circular disc movements was 0.72mm for the WAVE sensors and 0.14mm for the VOX sensors. There was no significant difference between the WAVE and the VOX in the number of missing frames.
Conclusions: In general, the VOX system significantly outperformed the WAVE on measures of both static precision and dynamic accuracy (automated and manual). For both systems, positional precision and spatial variability were influenced by the sensors' position relative to the field generator unit (FGU; worse when further away).
Judicial decision classification using Natural Language Processing and machine learning has received much attention in the last decade. While many studies claim to 'predict judicial decisions', most of them only classify already made judgements. Likely due to the lack of data, there have been only a few studies that discuss the data and the methods to forecast future judgements of the courts on the basis of data available before the court judgement is known. Besides proposing a more consistent and precise terminology, as classification and forecasting each have different uses and goals, we release a first benchmark dataset consisting of documents of the European Court of Human Rights to address this task. The dataset includes raw data as well as pre-processed text of final judgements, admissibility decisions and communicated cases. The latter are published by the Court for pending applications (generally) many years before the case is judged, allowing one to forecast judgements for pending cases. We establish a baseline for this task and illustrate that it is a much harder task than simply classifying judgements.
For many (minority) languages, the resources needed to train large models are not available. We investigate the performance of zero-shot transfer learning with as little data as possible, and the influence of language similarity in this process. We retrain the lexical layers of four BERT-based models using data from two low-resource target language varieties, while the Transformer layers are independently fine-tuned on a POS-tagging task in the model's source language. By combining the new lexical layers and fine-tuned Transformer layers, we achieve high task performance for both target languages. With high language similarity, 10MB of data appears sufficient to achieve substantial monolingual transfer performance. Monolingual BERT-based models generally achieve higher downstream task performance after retraining the lexical layer than multilingual BERT, even when the target language is included in the multilingual model.
This paper reviews data collection practices in electromagnetic articulography (EMA) studies, with a focus on sensor placement. It consists of three parts: in the first part, we introduce electromagnetic articulography as a method. In the second part, we focus on existing data collection practices. Our overview is based on a literature review of 905 publications from a large variety of journals and conferences, identified through a systematic keyword search in Google Scholar. The review shows that experimental designs vary greatly, which in turn may limit researchers' ability to compare results across studies. In the third part of this paper we describe an EMA data collection procedure which includes an articulatory-driven strategy for determining where to position sensors on the tongue without causing discomfort to the participant. We also evaluate three approaches for preparing (NDI Wave) EMA sensors reported in the literature with respect to the duration the sensors remain attached to the tongue: 1) attaching out-of-the-box sensors, 2) attaching sensors coated in latex, and 3) attaching sensors coated in latex with an additional latex flap. Results indicate no clear general effect of sensor preparation type on adhesion duration. A subsequent exploratory analysis reveals that sensors with the additional flap tend to adhere for shorter times than the other two types, but that this pattern is inverted for the most posterior tongue sensor.
Background: Most epidemiological studies show a decrease of internalizing disorders at older ages, but it is unclear how the prevalence exactly changes with age, and whether there are different patterns for internalizing symptoms and traits, and for men and women. This study investigates the impact of age and sex on the point prevalence across different mood and anxiety disorders, internalizing symptoms, and neuroticism.
Methods: We used cross-sectional data on 146,315 subjects, aged 18-80 years, from the Lifelines Cohort Study, a Dutch general population sample. Between 2012-2016, five current internalizing disorders - major depression, dysthymia, generalized anxiety disorder, social phobia and panic disorder - were assessed according to DSM-IV criteria. Depressive symptoms, anxiety symptoms, neuroticism, and negative affect were also measured. Generalized additive models were used to identify nonlinear patterns of internalizing disorders, symptoms and traits over lifetime, and to investigate sex differences.
Results: The point prevalence of internalizing disorders generally increased between the ages of 18-30 years, stabilized between 30-50, and decreased after age 50. The patterns of internalizing symptoms and traits were different. Negative affect and neuroticism gradually decreased after age 18. Women reported more internalizing disorders than men, but the relative difference remained stable across age (relative risk ~1.7).
Conclusions: The point prevalence of internalizing disorders was typically highest between age 30-50, but there were differences between the disorders, which could indicate differences in etiology. The relative gap between the sexes remained similar across age, suggesting that changes in sex hormones around the menopause do not significantly influence women's risk of internalizing disorders.
In this paper we present the web platform JURI SAYS that automatically predicts decisions of the European Court of Human Rights based on communicated cases, which are published by the court early in the proceedings and are often available many years before the final decision is made. Our system therefore predicts future judgements of the court. The platform is available at jurisays.com and shows the predictions compared to the actual decisions of the court. It is automatically updated every month by including the prediction for the new cases. Additionally, the system highlights the sentences and paragraphs that are most important for the prediction (i.e. violation vs. no violation of human rights).
We present a new comprehensive dataset for the unstandardised West-Germanic language Low Saxon covering the last two centuries, the majority of modern dialects and various genres, which will be made openly available in connection with the final version of this paper. Since so far no such comprehensive dataset of contemporary Low Saxon exists, this provides a great contribution to NLP research on this language. We also test the use of this dataset for dialect classification by training a few baseline models comparing statistical and neural approaches. The performance of these models shows that in spite of an imbalance in the amount of data per dialect, enough features can be learned for a relatively high classification accuracy.
Alcohol intoxication is known to affect many aspects of human behavior and cognition; one of such affected systems is articulation during speech production. Although much research has revealed that alcohol negatively impacts pronunciation in a first language (L1), there is only initial evidence suggesting a potential beneficial effect of inebriation on articulation in a non-native language (L2). The aim of this study was thus to compare the effect of alcohol consumption on pronunciation in an L1 and an L2. Participants who had ingested different amounts of alcohol provided speech samples in their L1 (Dutch) and L2 (English), and native speakers of each language subsequently rated the pronunciation of these samples on their intelligibility (for the L1) and accent nativelikeness (for the L2). These data were analyzed with generalized additive mixed modeling. Participants' blood alcohol concentration indeed negatively affected pronunciation in L1, but it produced no significant effect on the L2 accent ratings. The expected negative impact of alcohol on L1 articulation can be explained by reduction in fine motor control. We present two hypotheses to account for the absence of any effects of intoxication on L2 pronunciation: (i) there may be a reduction in L1 interference on L2 speech due to decreased motor control or (ii) alcohol may produce a differential effect on each of the two linguistic subsystems.
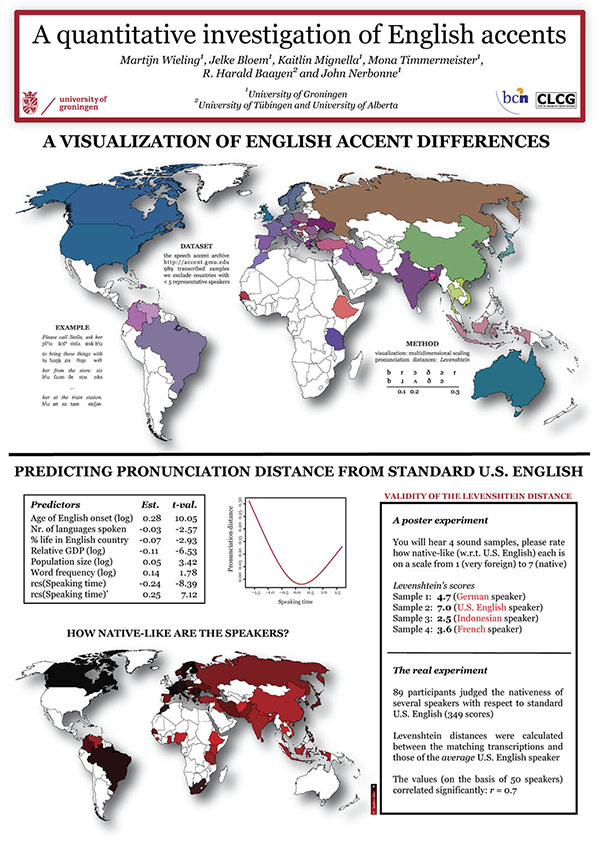
We present an acoustic distance measure for comparing pronunciations, and apply the measure to assess foreign accent strength in American-English by comparing speech of non-native American-English speakers to a collection of native American-English speakers. An acoustic-only measure is valuable as it does not require the time-consuming and error-prone process of phonetically transcribing speech samples which is necessary for current edit distance-based approaches. We minimize speaker variability in the data set by employing speaker-based cepstral mean and variance normalization, and compute word-based acoustic distances using the dynamic time warping algorithm. Our results indicate a strong correlation of r = -0.71 (p < 0.0001) between the acoustic distances and human judgments of native-likeness provided by more than 1,100 native American-English raters. Therefore, the convenient acoustic measure performs only slightly lower than the state-of-the-art transcription-based performance of r = -0.77. We also report the results of several small experiments which show that the acoustic measure is not only sensitive to segmental differences, but also to intonational differences and durational differences. However, it is not immune to unwanted differences caused by using a different recording device.
When courts started publishing judgements, big data analysis (i.e. largescale statistical analysis of case law and machine learning) within the legal domain became possible. By taking data from the European Court of Human Rights as an example, we investigate how Natural Language Processing tools can be used to analyse texts of the court proceedings in order to automatically predict (future) judicial decisions. With an average accuracy of 75% in predicting the violation of 9 articles of the European Convention on Human Rights our (relatively simple) approach highlights the potential of machine learning approaches in the legal domain. We show, however, that predicting decisions for future cases based on the cases from the past negatively impacts performance (average accuracy range from 58% to 68%). Furthermore, we demonstrate that we can achieve a relatively high classification performance (average accuracy of 65%) when predicting outcomes based only on the surnames of the judges that try the case.
This study focuses on an essential precondition for reproducibility in computational linguistics: the willingness of authors to share relevant source code and data. Ten years after Ted Pedersen's influential ``Last Words'' contribution in Computational Linguistics, we investigate to what extent researchers in computational linguistics are willing and able to share their data and code. We surveyed all 395 full papers presented at the 2011 and 2016 ACL Annual Meetings, and identified if links to data and code were provided. If working links were not provided, authors were requested to provide this information. While data was often available, code was shared less often. When working links to code or data were not provided in the paper, authors provided the code in about one third of cases. For a selection of ten papers, we attempted to reproduce the results using the provided data and code. We were able to reproduce the results approximately for half of the papers. For only a single paper we obtained the exact same results. Our findings show that even though the situation appears to have improved comparing 2016 to 2011, empiricism in computational linguistics still largely remains a matter of faith (Pedersen, 2008). Nevertheless, we are somewhat optimistic about the future. Ensuring reproducibility is not only important for the field as a whole, but also for individual researchers: below we show that the median citation count for studies with working links to the source code are higher.
We conduct the first experiment in the literature in which a novel is translated automatically and then post-edited by professional literary translators. Our case study is Warbreaker, a popular fantasy novel originally written in English, which we translate into Catalan. We translated one chapter of the novel (over 3,700 words, 330 sentences) with two data-driven approaches to Machine Translation (MT): phrase-based statistical MT (PBMT) and neural MT (NMT). Both systems are tailored to novels; they are trained on over 100 million words of fiction. In the post-editing experiment, six professional translators with previous experience in literary translation translate subsets of this chapter under three alternating conditions: from scratch (the norm in the novel translation industry), post-editing PBMT, and post-editing NMT. We record all the keystrokes, the time taken to translate each sentence, as well as the number of pauses and their duration. Based on these measurements, and using mixed-effects models, we study post-editing effort across its three commonly studied dimensions: temporal, technical and cognitive. We observe that both MT approaches result in increases in translation productivity: PBMT by 18%, and NMT by 36%. Post-editing also leads to reductions in the number of keystrokes: by 9% with PBMT, and by 23% with NMT. Finally, regarding cognitive effort, post-editing results in fewer (29% and 42% less with PBMT and NMT respectively) but longer pauses (14% and 25%).
In phonetics, many datasets are encountered which deal with dynamic data collected over time. Examples include diphthongal formant trajectories and articulator trajectories observed using electromagnetic articulography. Traditional approaches for analyzing this type of data generally aggregate data over a certain timespan, or only include measurements at a fixed time point (e.g., formant measurements at the midpoint of a vowel). In this paper, I discuss generalized additive modeling, a non-linear regression method which does not require aggregation or the pre-selection of a fixed time point. Instead, the method is able to identify general patterns over dynamically varying data, while simultaneously accounting for subject and item-related variability. An advantage of this approach is that patterns may be discovered which are hidden when data is aggregated or when a single time point is selected. A corresponding disadvantage is that these analyses are generally more time consuming and complex. This tutorial aims to overcome this disadvantage by providing a hands-on introduction to generalized additive modeling using articulatory trajectories from L1 and L2 speakers of English within the freely available R environment. All data and R code is made available to reproduce the analysis presented in this paper.
In this study, we investigate crosslinguistic patterns in the alternation between UM, a hesitation marker consisting of a neutral vowel followed by a final labial nasal, and UH, a hesitation marker consisting of a neutral vowel in an open syllable. Based on a quantitative analysis of a range of spoken and written corpora, we identify clear and consistent patterns of change in the use of these forms in various Germanic languages (English, Dutch, German, Norwegian, Danish, Faroese) and dialects (American English, British English), with the use of UM increasing over time relative to the use of UH. We also find that this pattern of change is generally led by women and more educated speakers. Finally, we propose a series of possible explanations for this surprising change in hesitation marker usage that is currently taking place across Germanic languages.
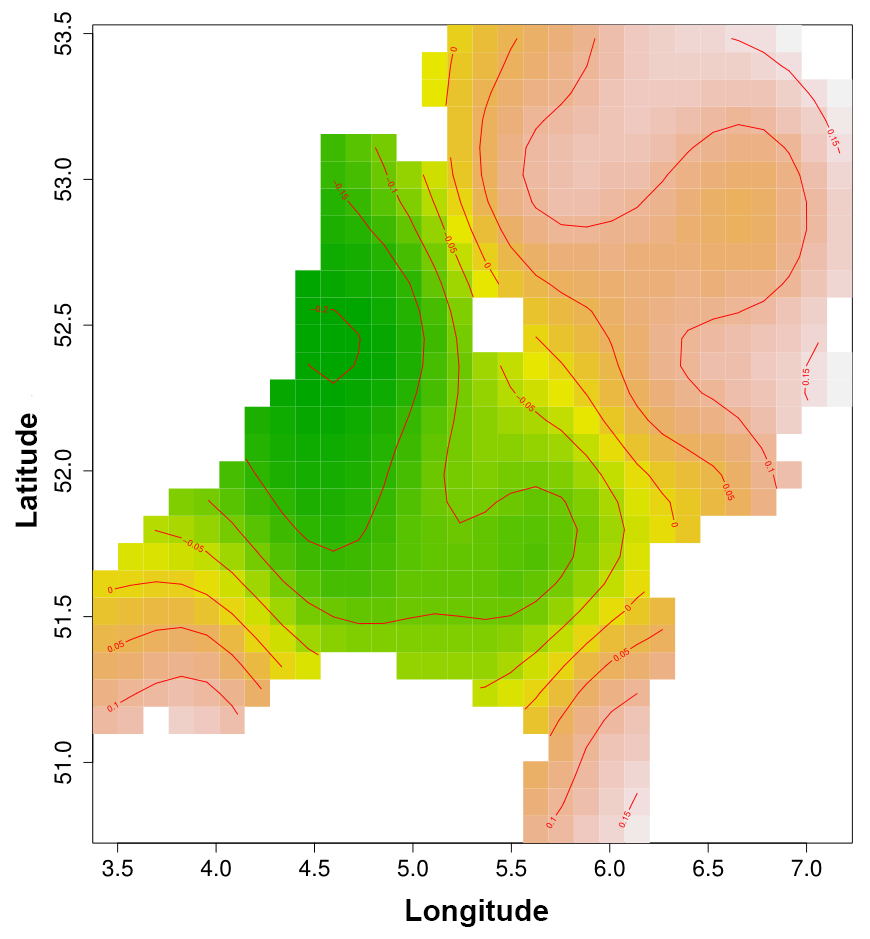
The present study uses electromagnetic articulography, by which the position of tongue and lips during speech is measured, for the study of dialect variation. By using generalized additive modeling to analyze the articulatory trajectories, we are able to reliably detect aggregate group differences, while simultaneously taking into account the individual variation of dozens of speakers. Our results show that two Dutch dialects show clear differences in their articulatory settings, with generally a more anterior tongue position in the dialect from Ubbergen in the southern half of the Netherlands than in the dialect of Ter Apel in the northern half of the Netherlands. A comparison with formant-based acoustic measurements further reveals that articulography is able to reveal interesting structural articulatory differences between dialects which are not visible when only focusing on the acoustic signal.
In this study we investigate the effect of age of acquisition (AoA) on grammatical processing in second language learners as measured by event-related brain potentials (ERPs). We compare a traditional analysis involving the calculation of averages across a certain time window of the ERP waveform, analyzed with categorical groups (early vs. late), with a generalized additive modeling analysis, which allows us to take into account the full range of variability in both AoA and time. Sixty-six Slavic advanced learners of German listened to German sentences with correct and incorrect use of non-finite verbs and grammatical gender agreement. We show that the ERP signal depends on the AoA of the learner, as well as on the regularity of the structure under investigation. For gender agreement, a gradual change in processing strategies can be shown that varies by AoA, with younger learners showing a P600 and older learners showing a posterior negativity. For verb agreement, all learners show a P600 effect, irrespective of AoA. Based on their behavioral responses in an offline grammaticality judgment task, we argue that the late learners resort to computationally less efficient processing strategies when confronted with (lexically determined) syntactic constructions different from the L1. In addition, this study highlights the insights the explicit focus on the time course of the ERP signal in our analysis framework can offer compared to the traditional analysis.
Dialectometry applies computational and statistical analyses within dialectology, making work more easily replicable and understandable. This survey article first reviews the field briefly in order to focus on developments in the past five years. Dialectometry no longer focuses exclusively on aggregate analyses, but rather deploys various techniques to identify representative and distinctive features with respect to areal classifications. Analyses proceeding explicitly from geostatistical techniques have just begun. The exclusive focus on geography as explanation for variation has given way to analyses combining geographical, linguistic, and social factors underlying language variation. Dialectometry has likewise ventured into diachronic studies and has also contributed theoretically to comparative dialectology and the study of dialect diffusion. Although the bulk of research involves lexis and phonology, morphosyntax is receiving increasing attention. Finally, new data sources and new (online) analytical software are expanding dialectometry's remit and its accessibility.
This study uses a generalized additive mixed-effects regression model to predict lexical differences in Tuscan dialects with respect to standard Italian. We used lexical information for 170 concepts used by 2,060 speakers in 213 locations in Tuscany. In our model, geographical position was found to be an important predictor, with locations more distant from Florence having lexical forms more likely to differ from standard Italian. In addition, the geographical pattern varied significantly for low- versus high-frequency concepts and older versus younger speakers. Younger speakers generally used variants more likely to match the standard language. Several other factors emerged as significant. Male speakers as well as farmers were more likely to use lexical forms different from standard Italian. In contrast, higher-educated speakers used lexical forms more likely to match the standard. The model also indicates that lexical variants used in smaller communities are more likely to differ from standard Italian. The impact of community size, however, varied from concept to concept. For a majority of concepts, lexical variants used in smaller communities are more likely to differ from the standard Italian form. For a minority of concepts, however, lexical variants used in larger communities are more likely to differ from standard Italian. Similarly, the effect of the other community- and speaker-related predictors varied per concept. These results clearly show that the model succeeds in teasing apart different forces influencing the dialect landscape and helps us to shed light on the complex interaction between the standard Italian language and the Tuscan dialectal varieties. In addition, this study illustrates the potential of generalized additive mixed-effects regression modeling applied to dialect data.
I frequently teach (invited) statistics courses for linguists focusing on generalized additive modeling.This technique, which is also able to take into account subject- and item-related variability (i.e. similar to mixed-effects regression) is important as it allows to model complex non-linear relationships between predictors and the dependent variable (e.g., time-series data such as EEG data). I've been invited to teach these courses at (e.g.,) Cambridge, Montréal and Toulouse. Slides (which are regularly updated) of these courses can be found here. If you are interested in this type of statistics course (generally ranging from two to five days), you are welcome to contact me. Note that I do ask a fee for teaching these courses.




Our Gronings app 'Van Old noar Jong' has launched and can be freely downloaded for Apple and Android. The app is integrated in a ten-week lesson series about the regional language Gronings for primary schools. Interested schools can order all material (including a copy of De Gruvvalo) for free via the website of the University of Groningen Scholierenacademie. The launch was covered by various news media, including the Dutch national Jeugdjournaal (see News coverage, below).
As of February 2021, we have a mobile laboratory available for our outreach initiatives and conducting research in the field: SPRAAKLAB. SPRAAKLAB has all the facilities necessary for collecting high-quality data and running various types of experiments in linguistics: from acoustic and articulatory data collection to eye-tracking and EEG using portable equipment. Below you can see the launch video of SPRAAKLAB. This launch was covered by various news media, including RTV Noord (see News coverage, below). With SPRAAKLAB, we often visit public engagement activities and festivals. For example, we have participated in Noorderzon (both in 2021 and 2022), Zwarte Cross (in 2022 and planned for 2023), and Expeditie Next (in 2022).

In August 2019, Dr. Gregory Mills and I investigated how language evolves and changes using a interactive game between two players. It was an incredible experience and we were able to collect speech production data for about 75 pairs of speakers during only three days! Our participation was made possible through financial contributions of the University of Groningen, the Young Academy Groningen and the Groningen University Fund. Below you can see an impression of this event. The event was covered by various news media, including NPO Radio 1 (see News coverage, below).

In August 2018, we investigated the influence of alcohol on native and non-native speech using ultrasound tongue imaging. It was an incredible experience and we were able to collect speech production data for about 150 speakers during only three days! Our participation was made possible through financial contributions of the University of Groningen, the Young Academy Groningen and the Groningen University Fund. Below you can see an impression of this event. The event was covered by various national news media, including NPO Radio 1 (see News coverage, below).

We enjoy demonstrating how we collect data on tongue and lip movement during speech. If you'd like a demonstration at your school or event, please contact me. Below you can see an impression of my team at the Experiment Event for children organized by De Jonge Akademie, the NS, the Spoorwegmuseum, and Quest Junior.

Through a project grant of De Jonge Akademie, I was able to create a comic about my research (designed and drawn by Lorenzo Milito and Ruggero Montalto). You can download it here for free. Please contact me if you would like to receive a printed copy of the Dutch version of the comic (as long as supplies last).



(Note that especially the English news coverage in 2014 got many details wrong, see this Language Log post.)







{kind=link}
{kind=link}
{kind=link}